I created my first ever R package and got it released onto CRAN in March 2019. It’s taken me a while to get round to actually writing about this which tells me that despite many years of trying to overcome procrastination, I’m obviously still not there! The package is actually an RStudio addin called objectremover that helps you to quickly remove objects stored in memory (specifically objects saved in the Global environment) within an R session. The main features include removing objects by
- Starting pattern of object name
- Ending pattern of object name
- Regular expression
- Object type (dataframe, function and other)
This is a quick demo of objectremover in action.
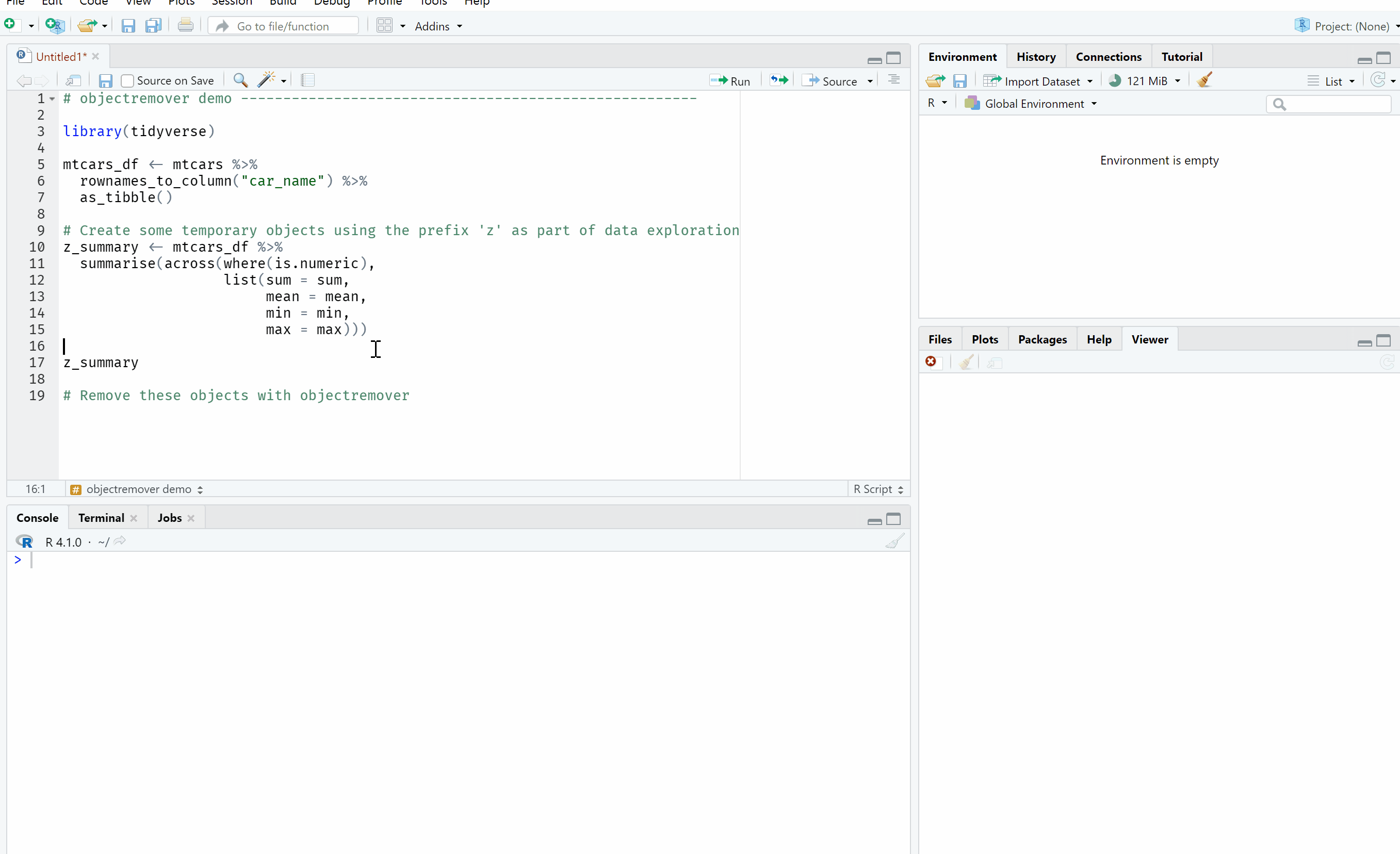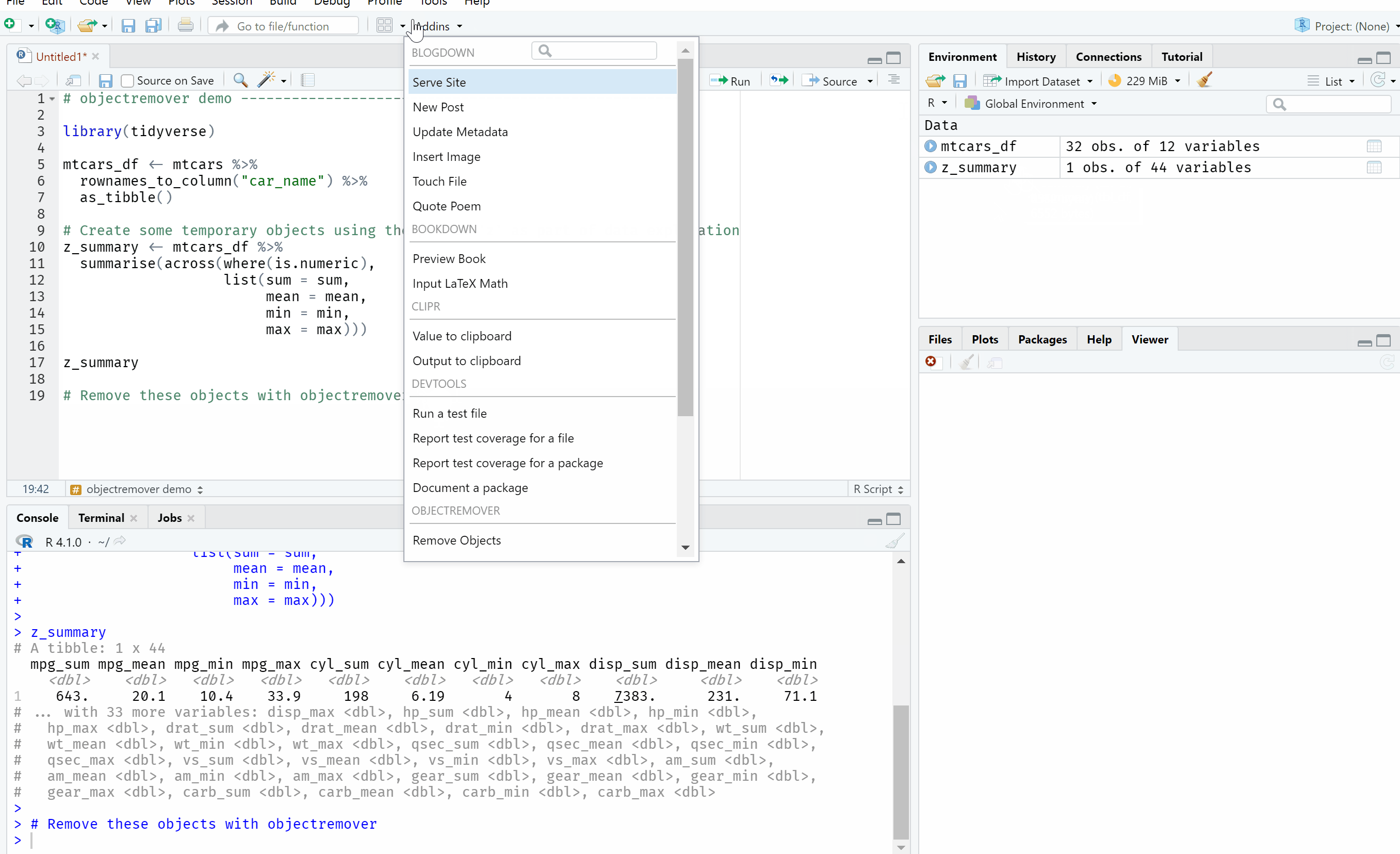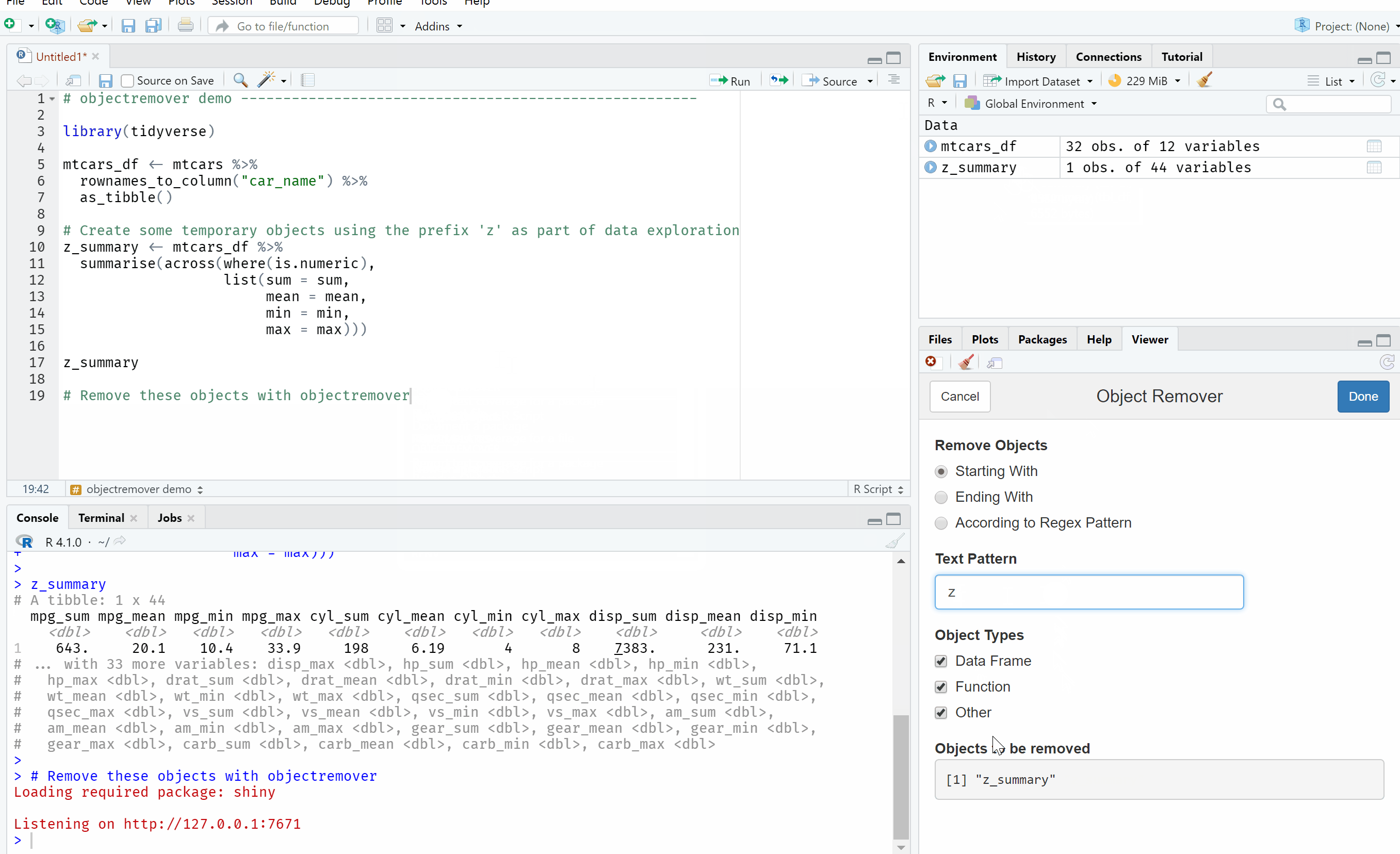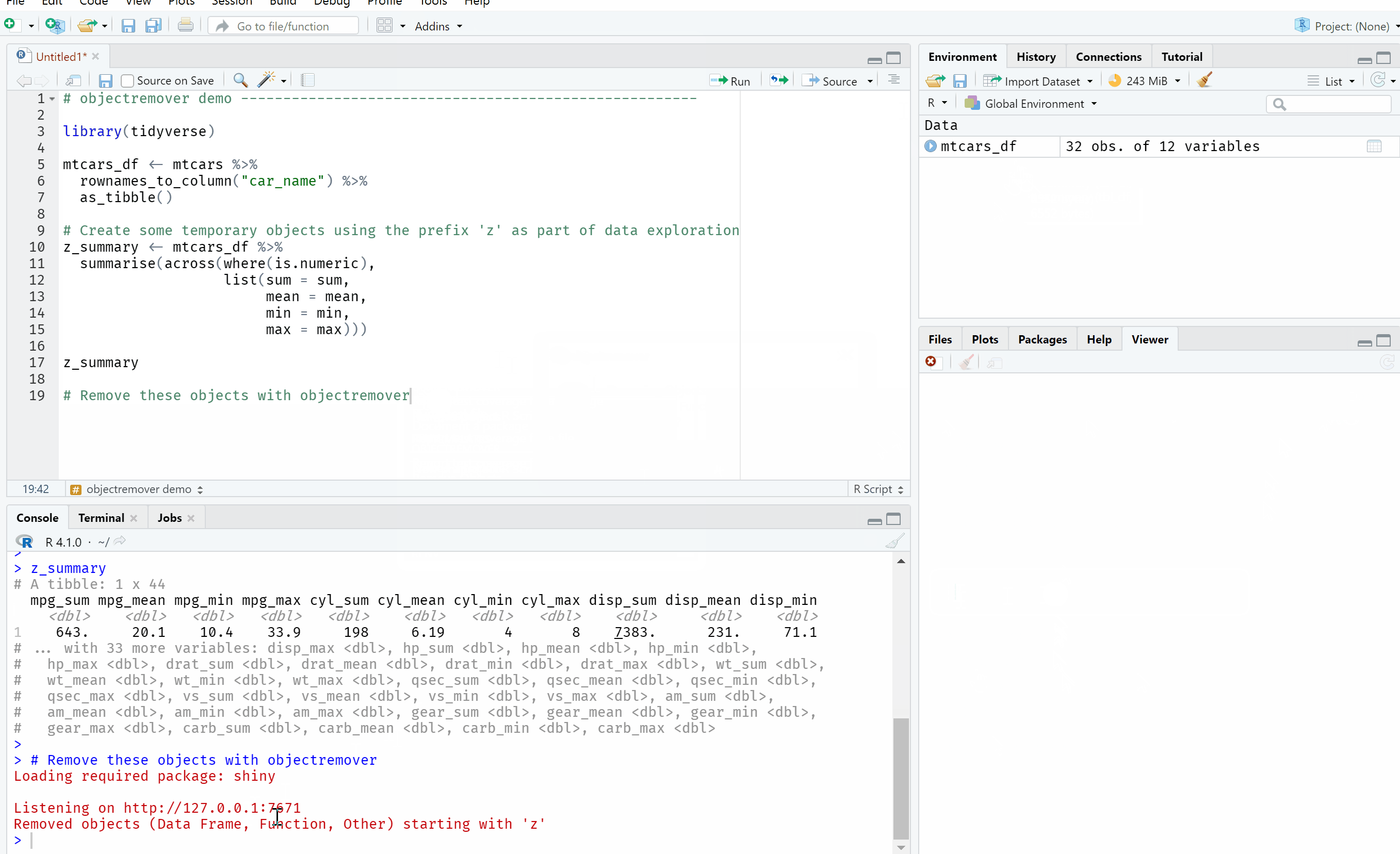
I made sure to include a couple of safety features to help ensure that you don’t remove objects by mistake. Firstly, it displays what objects will be removed based on the options you’ve selected in real-time and when you click ‘Done’, another warning popup box appears to get a second confirmation that you want to remove these objects. I put this warning popup in as you could remove all saved objects (perhaps by mistake) if, for example, you use a regular expression with no pattern.
I recently also got objectremover added to the list of addins started and maintained by Dean Attali.
A Learning Exercise
Creating this package was largely a learning exercise for me and I really learned loads in the process. To create the package, I tried the usethis package for the first time to help get various things set up. When I got to the stage where the package was mostly developed, I tested that the package builds successfully in various operating systems and R versions using Travis CI and the R-hub builder (again, this was the first time I’ve used these tools). A continous integration service like Travis is useful for ensuring that the package still builds properly whenever you make changes to the package and push onto Github. I even had a go at creating a hex sticker for the package (with the help of the hexsticker package) and anybody that knows me at all knows that this isn’t the sort of thing I’m good at! But I’m happy I gave it a go as that’s the only way to get better.
When I submitted to CRAN, the package got knocked back a few times but I followed the wise advice of Hadley Wickham to not take any criticism personally (particularly as the CRAN maintainers are very busy people and have a hard job) and just tackled all the obstacles in a respectful manner. This advice probably applies to many things in life beyond building R packages so I try to follow this approach as much as humanly possible (but as I am actually human, it stands to reason that I still fail in this regard – and more often than I’d like as well unfortunately!).
Workflow
The idea for the package came about as I tend to create a lot of temporary objects in R as I work through analyses and I just wanted a quick way to remove these objects. I often call these objects with names starting with the letter ‘z’ so that they will be easy to spot. This was something I learned from my former PhD supervisor and has actually become pretty invaluable as naming things is something that can sometimes cause me more stress and take up more energy than you would imagine for something this basic and fundamental! So having a way of removing the need for this decision-making helps to focus on solving problems quickly rather than putting energy into things such as naming objects.
Having said this, I do always go through my code carefully after I’ve solved the problems I’m working on and tidy the script up to make sure I can understand everything I’ve done. This process is sometimes known as code refactoring. It is something that is sometimes overlooked but is really important for ensuring that you and others can better understand what a script is doing. This quote sums up the benefits pretty well.
By continuously improving the design of code, we make it easier and easier to work with. This is in sharp contrast to what typically happens: little refactoring and a great deal of attention paid to expediently adding new features. If you get into the hygienic habit of refactoring continuously, you’ll find that it is easier to extend and maintain code.
— Joshua Kerievsky
Part of what I do for this includes putting in section breaks into my script (in RStudio, the shortcut to do this is ctrl+shift+R) to split things into more manageable blocks. I’ll also give meaningful names to objects that I do want to track, particularly for longer projects. For example, there may be several data processing stages involved in going from a raw dataset up to the dataset you use for analysis. I will usually create a number of temporary objects (beginning with ‘z’) that help me get to the analysis dataset (often via various joins between datasets). In this case, the raw and analysis datasets would get meaningful names and the temporary objects could be removed. At the end, I may save the raw and analysis datasets into an R workspace (or as RDS format) that can be easily loaded into scripts created for other parts of a long project.
Anyway that’s just an example of a workflow that I sometimes use and find pretty efficient for long projects. I’m sure there are many other great ways to work efficiently in creating outputs for long projects so if you know of some, please let me know as I always like to hear about ways to work efficiently in R. Oh and of course, I hope some people find objectremover useful!